

4-min read
Disclaimer: I do not support penetration testing into national systems or any systems for that matter without authorized permission. This was purely an academic exercise.
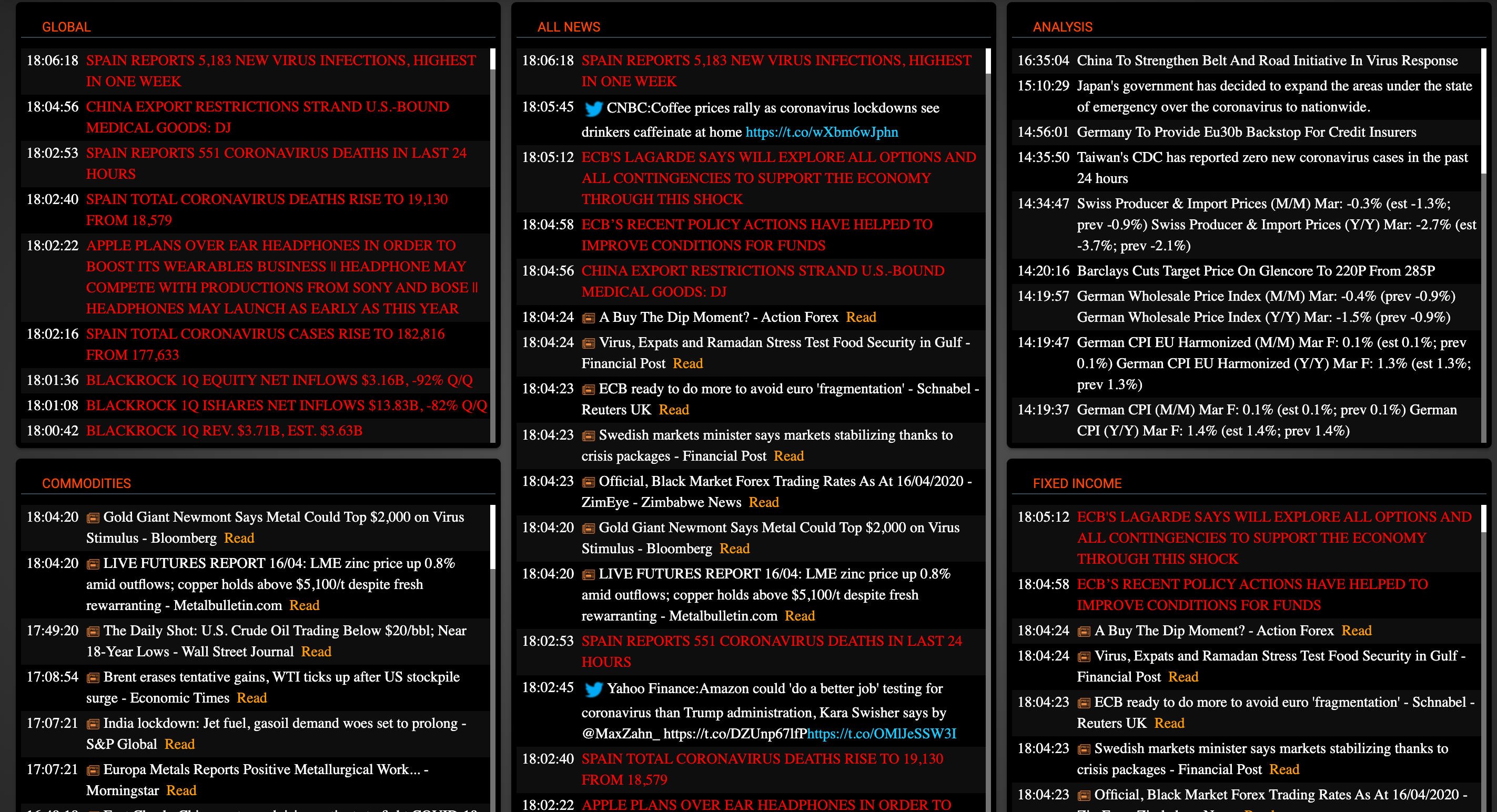
I came across an interesting SaaS product on Twitter today. They specialize in ‘up-to-the-second broadcast reports and headlines’. I took a look:
Permission
The application looked pretty bare-bones to me, so I went digging, and managed to reverse their single source of truth in a few minutes. All their data is packed into a single API request, in this format:
{
"_id": "5e982ce405a53b29273723f2",
"createdAtDate": "2020-04-16T10:01:08.897Z",
"createdAt": "1587031268897",
"message": "BLACKROCK 1Q ISHARES NET INFLOWS $13.83B, -82% Q/Q",
"cssClass": "Red",
"category": "Global",
"__v": 0,
"msgSrc": "<COMPANY_NAME>",
"deleted": false,
"action": "add"
}Message Object
Sample cURL if you’re so inclined —
$ curl --location --request GET 'https://api.company.com/message' \ --header 'x-auth: API_KEY_HERE' \ --header 'from: app'& Node.js which works out of the box —
var request = require('request');
var options = {
'method': 'GET',
'url': 'https://api.company.com/message',
'headers': {
'x-auth': 'API_KEY_HERE',
'from': 'app'
}
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});I was about to call it a day when I noticed that the website constantly pushed new updates to the top of the stack. Did they had a persistent connection I might have missed?
Deeper
Waiting for a few more minutes yielded results. Data was coming from a separate web socket, and below are the payloads I received (cleaned for posterity purposes):
> {"sid":"S_ID","upgrades [],"pingInterval":25000, "pingTimeout":5000}This is the JSON handshake data from socket.io. I guess they overrode the default web socket timeout of 30 seconds and changed it to 25. Onwards:
> ["feeds", {
"title": "Company global feeds",
"description": "",
"generator": "RSS for Node",
"site_url": "https://www.company.com/",
"geoRSS": false,
"custom_namespaces": {},
"custom_elements": [],
"items": [{
"title": "RUSSIAN ROUBLE EXTENDS GAINS, FIRMS 1% ON THE DAY TO 74.05 VS DOLLAR",
"description": "RUSSIAN ROUBLE EXTENDS GAINS, FIRMS 1% ON THE DAY TO 74.05 VS DOLLAR",
"guid": "5e98335705a53b292737242d",
"categories": ["Fixed_income"],
"enclosure": false,
"custom_elements": [null]
}]
}]This was a different structure compared to the previous single API call. I suspect this was for the RSS global feed, which is grabbed from Twitter, while anything in-house is a broadcastMsg Object. If it is a tweet, the Message Object is appended with two parameters - user and url respectively — and the msgSrc is swapped from <COMPANY_NAME> to twitter. They also send an XML along with this object which you can view here.
Below is the command I used to run the web socket connection on my terminal:
$ wscat -c 'wss://api.company.com/socket.io/?token=API_KEY_HERE&EIO=3&transport=websocket'npm install -g wscat, if you don’t have it already since cURL doesn’t support web sockets out of the box.
Naturally, this lasted only for the allotted time before error-ing out with code 1005.
Epilogue & Mitigation
What does this mean? What can you even do with this?
Well, their entire USP was cracked in less than 30 minutes. I can potentially develop a front-end, start charging people and undercut by a significant amount — since I wouldn’t be generating/ handling/ processing any of the data.
Predatory pricing strategies aside, isn’t this a web socket connection and you’ll only be able to serve old data?
Shouldn’t be too much of a hassle to create a proper persistent connection.
I’m sure they have some unique token for each instance?
Yes, they do, but spinning up a Selenium instance, grabbing the unique token_id and then authenticating is trivial work.
But you were on a trial account. What happens when they close your account?
Use burner email accounts, rinse, and repeat. Don’t do this it is terrible and this is why companies shutter their free trials.
Increased spike in the number of connections to a single token?
Cache data on Redis and serve from my side.
What is the difference between you and
<COMPANY_NAME>then?
Uh, good question. I might be able to do a better job myself without jumping through all these hoops.
How can they prevent this?
Honestly, there aren’t many ways to restrict access to the data once it is on the website. I can just as easily scrape and create my own payload. The best way forward would be to use CORS properly, obfuscate data, randomize class names, and implement an efficient tracking system that automatically boots people misusing the service, or at the very least an identity check. Logging is imperative for proper mitigation. This still might be challenging to stop someone inclined to harvest company data but isn’t the cat-and-mouse game the fun part?